반응형
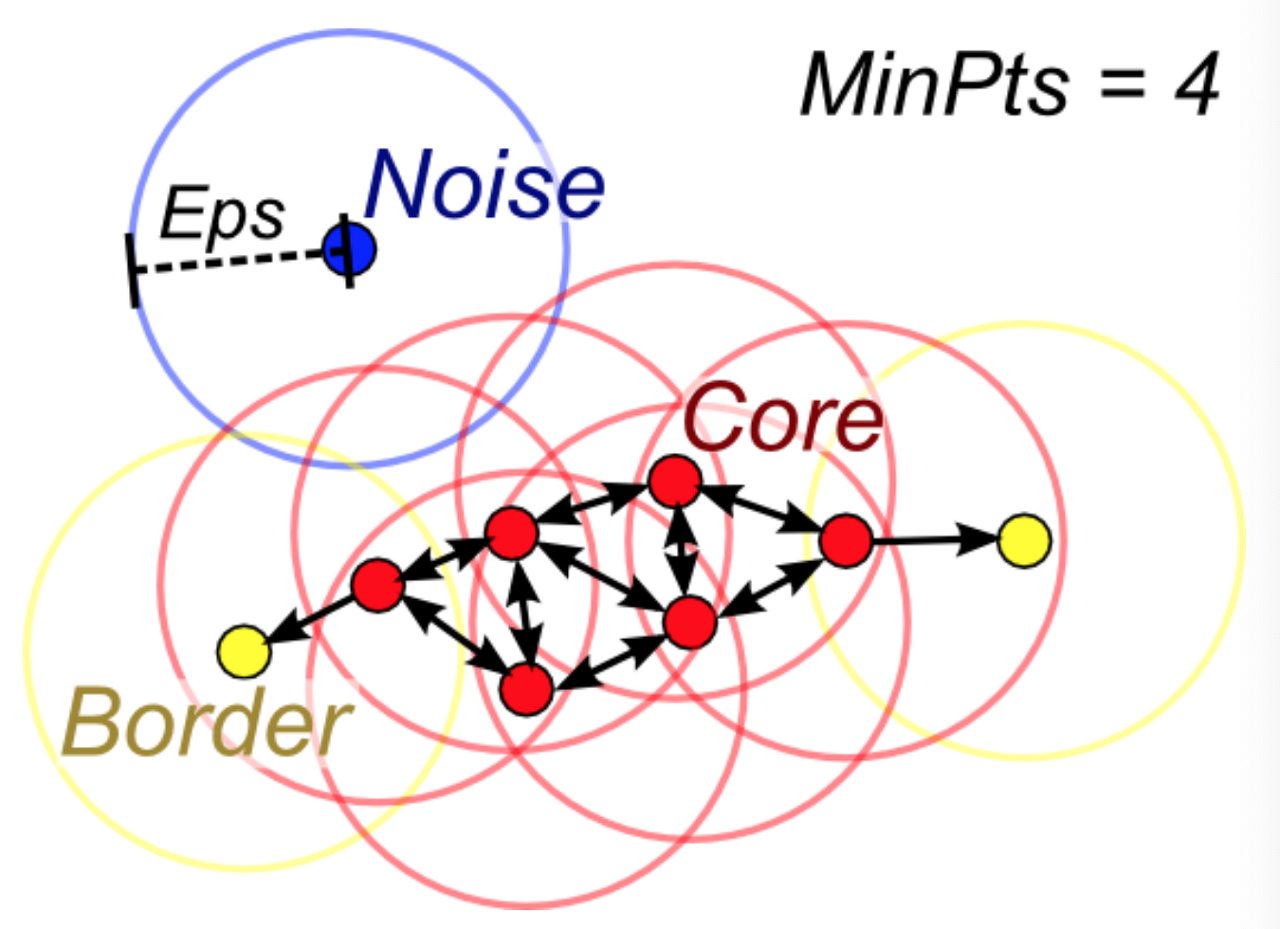
1. DBSCAN(Density-Based Spatial Clustering of Applications Noise)
공간 밀집도를 기반으로
코어 포인트, 보드 포인트를 정한다.
K-Means 클러스터링 방법은 단순하고 강력한 방법이지만
클러스터의 모양이 원형이 아닌 경우에는 잘 동작하지 않으며
클러스터의 갯수를 사용자가 지정해주어야 한다.
DBSCAN은 데이터가 밀집한 정도 즉 밀도를 이용하여 클러스터의 형태에 구애받지 않으며
클러스터의 갯수를 사용자가 지정할 필요가 없다.
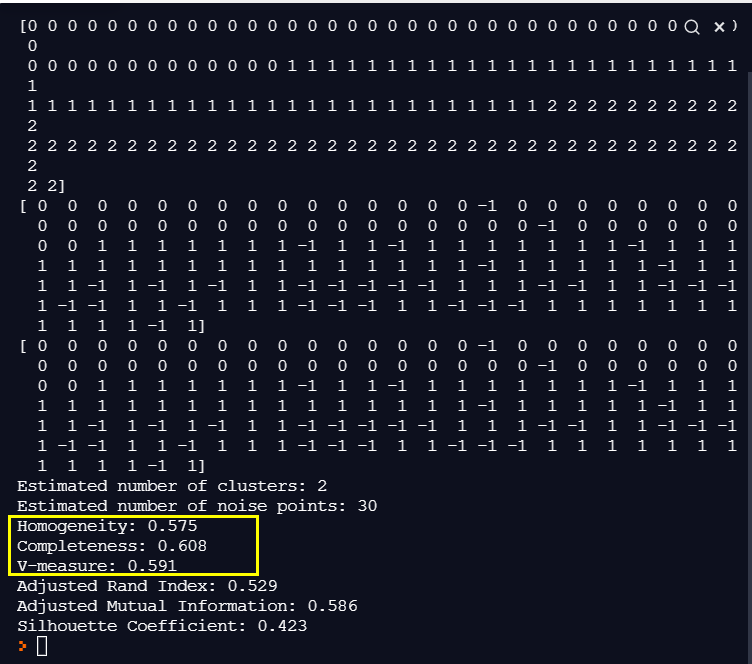
2. Iris 데이터를 DBSCAN으로 군집화하기
아래는 거리가 0.5 10개의 데이터가 있으면 군집화시키는 코드이다.
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import datasets
from sklearn import metrics
from sklearn.metrics.cluster import homogeneity_score, completeness_score,v_measure_score
iris = datasets.load_iris()
X = iris.data
y = iris.target
print(y)
model= DBSCAN(eps=0.5, min_samples=10)
model.fit(X)
print(model.labels_)
labels = model.labels_
print(labels)
core_samples_mask = np.zeros_like(labels, dtype=bool)
core_samples_mask[model.core_sample_indices_] = True
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print('Estimated number of clusters: %d' % n_clusters_)
print('Estimated number of noise points: %d' % n_noise_)
print("Homogeneity: %0.3f" % homogeneity_score(y, labels))
print("Completeness: %0.3f" % completeness_score(y, labels))
print("V-measure: %0.3f" %v_measure_score(y, labels))
print("Adjusted Rand Index: %0.3f" % metrics.adjusted_rand_score(y, labels))
print("Adjusted Mutual Information: %0.3f" % metrics.adjusted_mutual_info_score(y, labels))
print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X, labels))
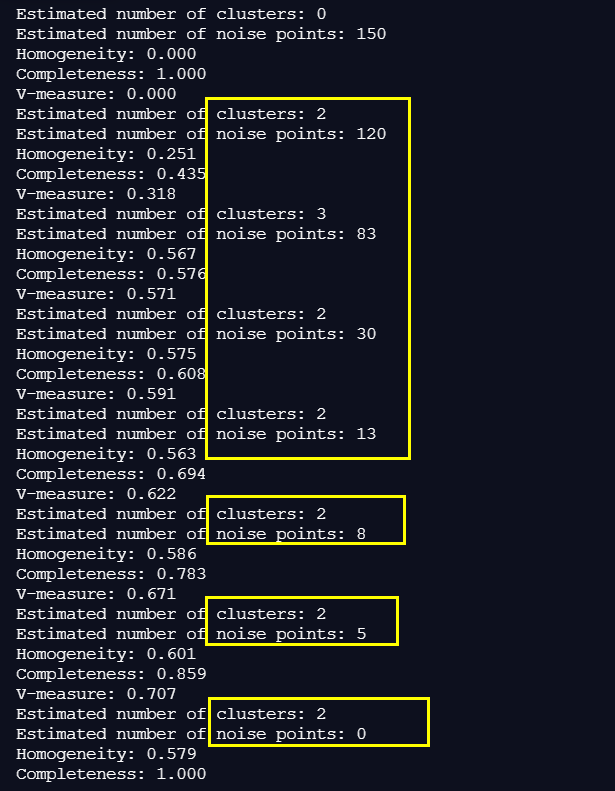
3. eps를 바꾸어가며 확인하기
eps를 0.1부터 시작하여 0.2, 0.3, 0.4로 1.0까지 높여본다.
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import datasets
from sklearn import metrics
from sklearn.metrics.cluster import homogeneity_score,completeness_score,v_measure_score
iris = datasets.load_iris()
X = iris.data
y = iris.target
print(y)
for i in range (1,10,1):
model= DBSCAN(eps=i*0.1, min_samples=10)
model.fit(X)
labels = model.labels_
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print('Estimated number of clusters: %d' % n_clusters_)
print('Estimated number of noise points: %d' % n_noise_)
print("Homogeneity: %0.3f" % homogeneity_score(y, labels))
print("Completeness: %0.3f" % completeness_score(y, labels))
print("V-measure: %0.3f" %v_measure_score(y, labels))
반응형
'프로그래밍 > 머신러닝' 카테고리의 다른 글
| 딥러닝 알아보기(인공지능, 머신러닝, 딥러닝의 관계)_파이썬으로 머신러닝 배우기 (0) | 2021.05.31 |
|---|---|
| 비지도학습(AgglomerativeClustering)_파이썬으로 머신러닝 배우기 (0) | 2021.05.26 |
| 비지도학습(K-mean)_파이썬으로 머신러닝 배우기 (0) | 2021.05.20 |
| iris 분류하기(K-NN모델)_파이썬으로 머신러닝 배우기 (0) | 2021.05.10 |
| 인공신경망(neural_network)_파이썬으로 머신러닝 배우기 (0) | 2021.05.05 |


