머신러닝의 학습 종류는
지도학습
비지도학습
강화학습
이렇게 3가지가 있다.
그 중 K-NN모델을 활용해 지도학습하는 방법을 살펴보자!
1. Confusion Matrix(평가 방법)

2. Confusion Matrix(평가 방법)의 Presicion(정확도), Recall(재현율), F1_scroe(점수)
F1_score : 정확도와 재현율을 균등하게 반영

3. 다양한 데이터 수집
UCI 에서 제공하는 다양한 데이터
archive.ics.uci.edu/ml/datasets.php
UCI Machine Learning Repository: Data Sets
archive.ics.uci.edu
Kaggle에서 제공하는 빅데이터
Find Open Datasets and Machine Learning Projects | Kaggle
Download Open Datasets on 1000s of Projects + Share Projects on One Platform. Explore Popular Topics Like Government, Sports, Medicine, Fintech, Food, More. Flexible Data Ingestion.
www.kaggle.com
data.gov(미국 정부에서 제공하는 데이터)
data.europa
aihub.or.kr 국내에서 제공하는 데이터
홈 | AI Hub
AI Hub(AI 허브)는 양질의 인공지능 학습용 데이터를 누구에게나 공개하여 지능 정보사회 발전에 도움
aihub.or.kr
4. Iris 데이터
통계학자(Fisher)가 정리한 붓꽃 데이터로
붓꽃의 3가지 종(setosa, Versicolor, Virginica)을 각각의 특성에 맞게 분류되어 있다.
5. 붓꽃 데이터셋 학습용, 테스트용 데이터 확인하기
붓꽃 데이터셋은 아래 링크에 가면 찾을 수 있다.
archive.ics.uci.edu/ml/datasets/iris
UCI Machine Learning Repository: Iris Data Set
Data Set Characteristics: Multivariate Number of Instances: 150 Area: Life Attribute Characteristics: Real Number of Attributes: 4 Date Donated 1988-07-01 Associated Tasks: Classification Missing Values? No Number of Web Hits: 3981751 Source: Creator:
archive.ics.uci.edu
굳이 데이터셋을 다운로드 받지 않아도 sklearn모듈에 붓꽃 데이터셋이 포함되어 있다~!
import numpy as np
import sklearn
#데이터 가져오기
from sklearn.datasets import load_iris
iris_dataset = load_iris()
print('iris_dataset의 키 : {}'.format(iris_dataset.keys()))
print(iris_dataset['DESCR'][:193] + '\n...')
print('특성의 이름 : {}'.format(iris_dataset['feature_names']))
print('data의 크기 : {}'.format(iris_dataset['data'].shape))
print('data의 처음 다섯 행: \n'.format(iris_dataset['data'][:5]))
print('타깃 : \n'.format(iris_dataset['target']))
print(iris_dataset)

학습용 데이터와 테스트 데이터 크기를 확인해보자!
70%는 학습용이고
30%는 테스트용이다.
import numpy as np
import sklearn
#데이터 가져오기
from sklearn.datasets import load_iris
iris_dataset = load_iris()
X = iris_dataset['data']
y = iris_dataset['target']
#훈련 데이터와 시험 데이터 나누기
from sklearn.model_selection import train_test_split
#150개의 일정 부분은 훈련용, 일정 부분은 테스트용
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
print('X_train 크기 : {}'.format(X_train.shape))
print('y_train 크기 : {}'.format(y_train.shape))
print('X_test 크기 : {}'.format(X_test.shape))
print('y_test 크기 : {}'.format(y_test.shape))

7. K-NN모델로 분류하기
Iris붓꽃을 K근접, 결정트리, 신경망, SVM, Emsemble으로 분류해볼것인데
우선 K-NN모델로 분류해보자!
import numpy as np
import sklearn
#데이터 가져오기
from sklearn.datasets import load_iris
iris_dataset = load_iris()
X = iris_dataset['data']
y = iris_dataset['target']
#훈련 데이터와 시험 데이터 나누기
from sklearn.model_selection import train_test_split
#150개의 일정 부분은 훈련용, 일정 부분은 테스트용
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=1)
model.fit(X_train, y_train)
#예측해보기
X_new = np.array([[4, 3.9, 1.1, 0.1]])
print('X_new.shape: {}'.format(X_new.shape))
prediction = model.predict(X_new)
print('예측 : {}'.format(prediction))
print('예측한 타깃의 이름 : {}'.format(iris_dataset['target_names'][prediction]))
#38개의 테스트 데이터
y_p = model.predict(X_test)
print('테스트 세트에 대한 예측값 : {}'.format(y_p))
print('테스트 세트에 대한 실제값 : {}'.format(y_test))
print('테스트 세트의 정확도 : {:.2f}'.format(np.mean(y_p == y_test)))
print('테스트 세트의 정확도 : {:.2f}'.format(model.score(X_test, y_test)))
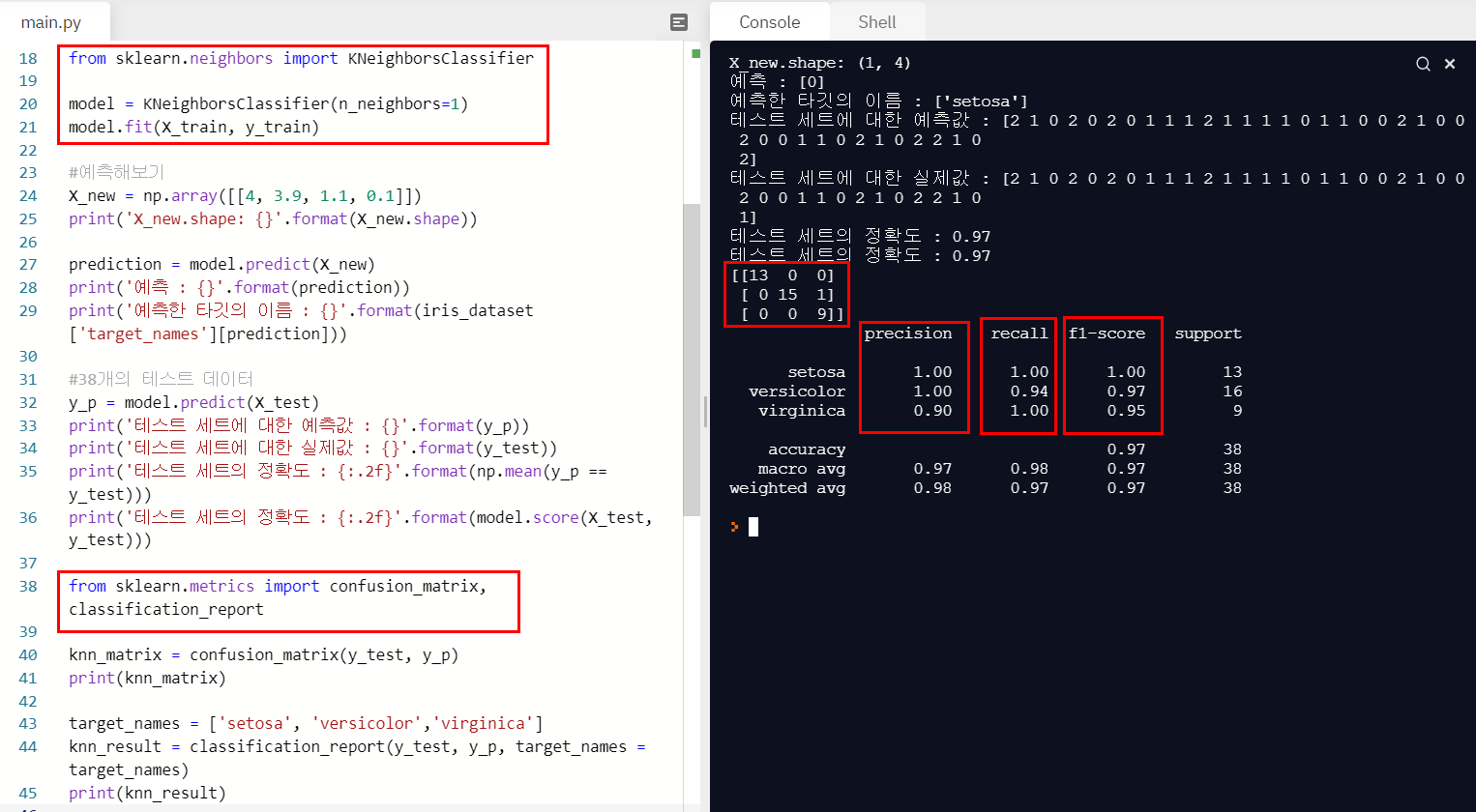
8. 사이트에 있는 iris 데이터를 활용하여 분류하기
import numpy as np
import pandas as pd
import sklearn
uci = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris_dataset=pd.read_csv(uci,header=None)
print(iris_dataset)
iris_dataset.columns=['SepalLength','SepalWidth','PetalLength','PetalWidth','Species']
print(iris_dataset)
X=iris_dataset[['SepalLength','SepalWidth', 'PetalLength','PetalWidth']]
print(X)
y=iris_dataset['Species']
print(y)
#훈련데이타와 시험 데이타 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y , random_state=0)
print("X_train 크기: {}".format(X_train.shape))
print("y_train 크기: {}".format(y_train.shape))
print("X_test 크기: {}".format(X_test.shape))
print("y_test 크기: {}".format(y_test.shape))
# 모델 만들기
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=1)
model.fit(X_train, y_train)
# 예측해 보기
X_new = np.array([[4, 3.9, 1.1, 0.1]])
print("X_new.shape: {}".format(X_new.shape))
prediction = model.predict(X_new)
print("예측: {}".format(prediction))
y_p = model.predict(X_test)
print("테스트 세트에 대한 예측값:\n {}".format(y_p))
print("테스트 세트에 대한 실제값:\n {}".format(y_test))
print("테스트 세트의 정확도: {:.2f}".format(np.mean(y_p == y_test)))
print("테스트 세트의 정확도: {:.2f}".format(model.score(X_test, y_test)))사이트에 있는 붓꽃 데이터를 그대로 가져와서 예측해볼 수 있다.

9. 인자를 바꾸어가며 확인해보기!
import numpy as np
import pandas as pd
import sklearn
uci = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
iris_dataset=pd.read_csv(uci,header=None)
print(iris_dataset)
iris_dataset.columns=['SepalLength','SepalWidth','PetalLength','PetalWidth','Species']
print(iris_dataset)
X=iris_dataset[['SepalLength','SepalWidth', 'PetalLength','PetalWidth']]
print(X)
y=iris_dataset['Species']
print(y)
#훈련데이타와 시험 데이타 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y , random_state=0)
print("X_train 크기: {}".format(X_train.shape))
print("y_train 크기: {}".format(y_train.shape))
print("X_test 크기: {}".format(X_test.shape))
print("y_test 크기: {}".format(y_test.shape))
# 모델 만들기
from sklearn.neighbors import KNeighborsClassifier
for i in (1,3,5,7):
for j in ('uniform', 'distance'):
for k in ('auto','ball_tree','kd_tree','brute'):
model = KNeighborsClassifier(n_neighbors=i, weights=j, algorithm=k)
model.fit(X_train, y_train)
y_p = model.predict(X_test)
relation_square =model.score(X_test, y_test)
from sklearn.metrics import confusion_matrix,classification_report
knn_matrix=confusion_matrix(y_test,y_p)
print(knn_matrix)
target_names = ['setosa', 'versicolor', 'virginica']
knn_result=classification_report(y_test,y_p,target_names=target_names)
print(knn_result)
print('\n')
print('\n')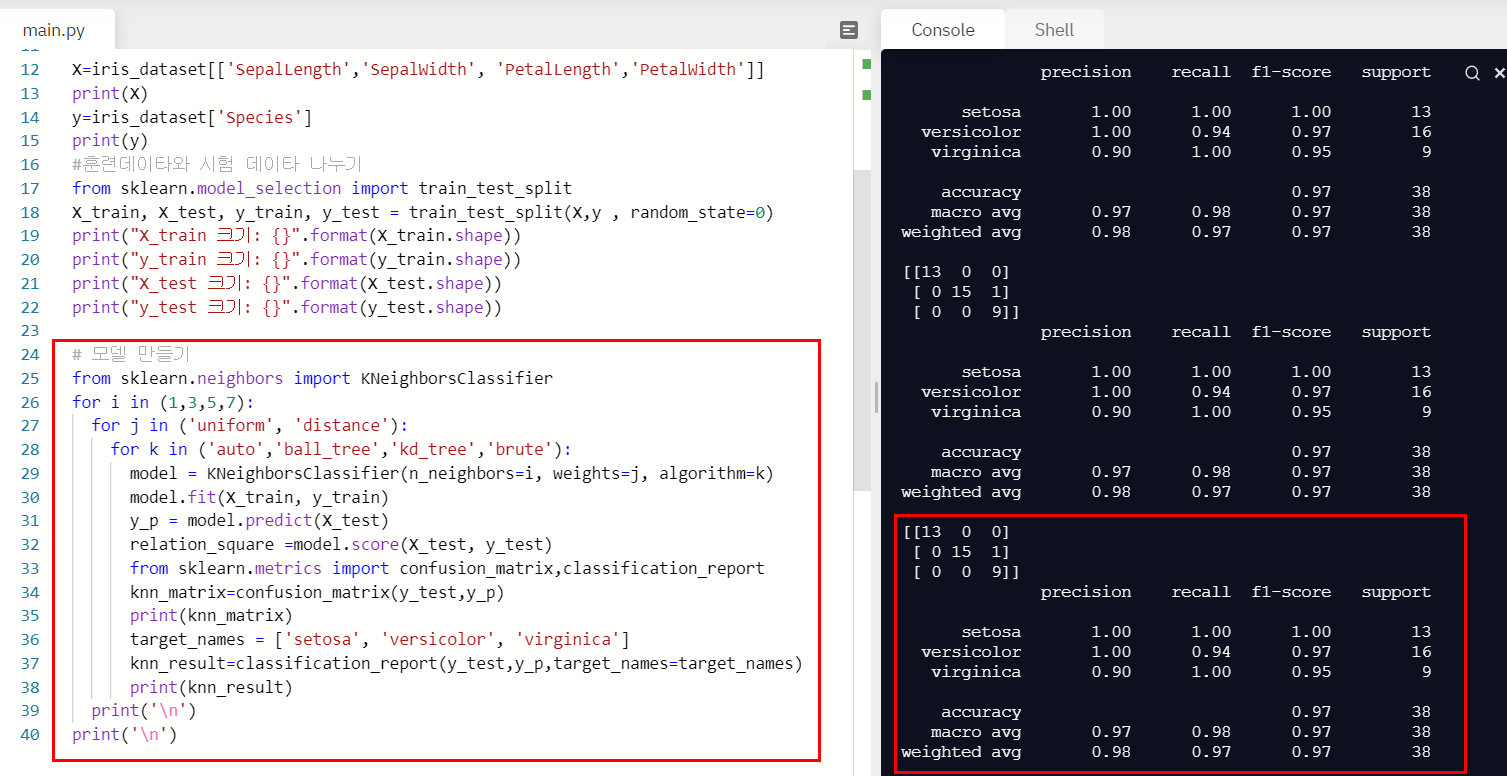
K-NN모델로 붓꽃 데이터를 가져와 분류해보았다.
어렵지만... 파이썬에 코드를 쓰는 방법을 익히면 여러 데이터를 가져와 분류해 볼 수 있을 듯 하다!
'프로그래밍 > 머신러닝' 카테고리의 다른 글
| 비지도학습(DBSCAN)_파이썬으로 머신러닝 배우기 (0) | 2021.05.24 |
|---|---|
| 비지도학습(K-mean)_파이썬으로 머신러닝 배우기 (0) | 2021.05.20 |
| 인공신경망(neural_network)_파이썬으로 머신러닝 배우기 (0) | 2021.05.05 |
| 결정 트리(Decision Tree)_파이썬으로 머신러닝 배우기 (0) | 2021.05.03 |
| k-근접 모델(KNeighborsRegressor)_파이썬으로 머신러닝 배우기 (0) | 2021.04.29 |



