반응형
파이썬으로 머신러닝 배우기
K-NN(nearest neighbor) 모델
K근접모델
1. K-NN알고리즘이란?
K-NN알고리즘은 지도 학습 알고리즘 이다.
가장 가까운 이웃끼리 범주화 하는 것을 의미한다.


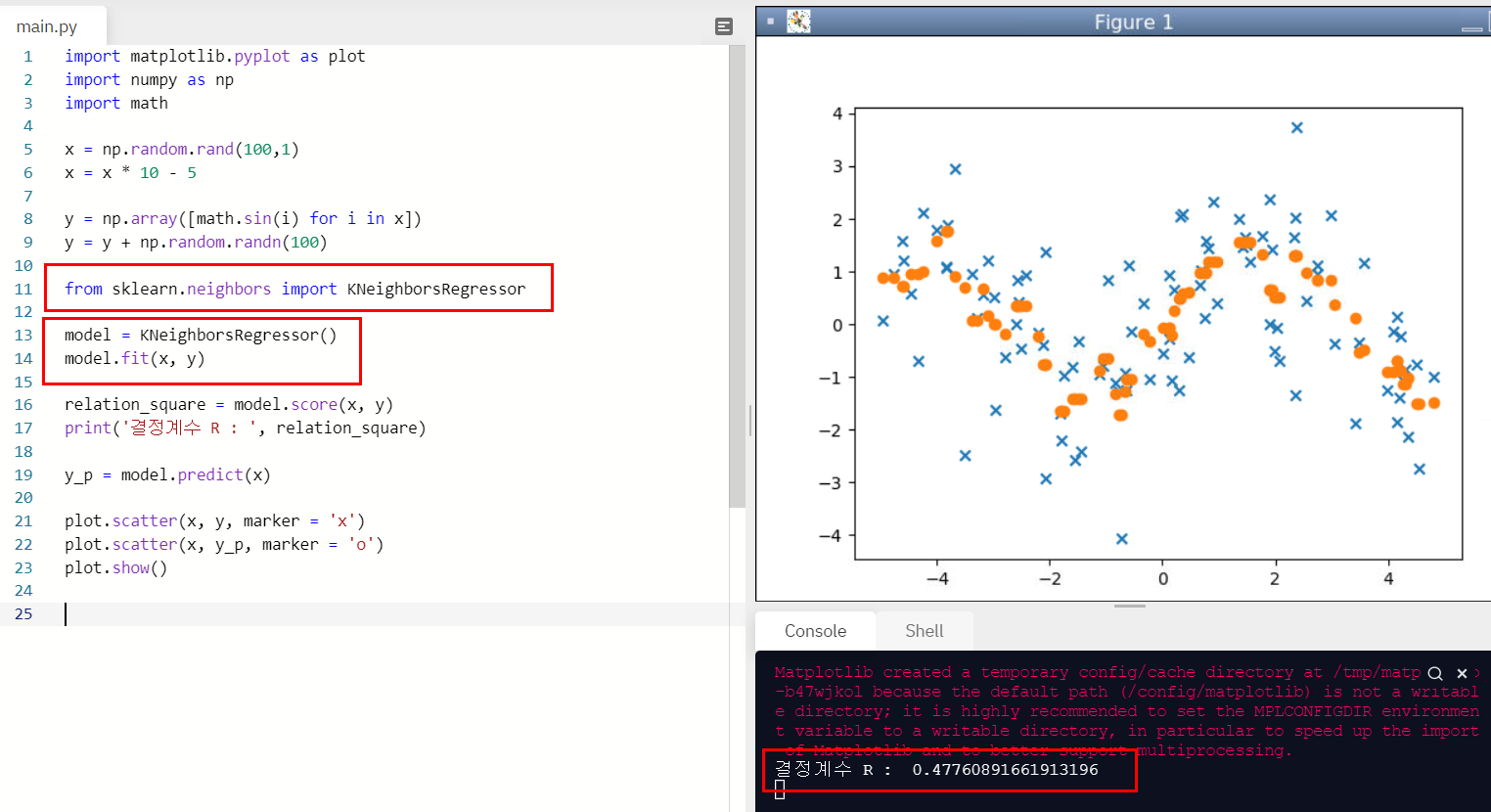
2. K-NN모델 테스트
import matplotlib.pyplot as plot
import numpy as np
import math
x = np.random.rand(100,1)
x = x * 10 - 5
y = np.array([math.sin(i) for i in x])
y = y + np.random.randn(100)
from sklearn.neighbors import KNeighborsRegressor
model = KNeighborsRegressor()
model.fit(x, y)
relation_square = model.score(x, y)
print('결정계수 R : ', relation_square)
y_p = model.predict(x)
plot.scatter(x, y, marker = 'x')
plot.scatter(x, y_p, marker = 'o')
plot.show()
3. K-NN 인자 조절
neighbors 는 기본적으로 5이다.
n_neighbors
weights = uniform, distance
algorithm {'auto', 'ball_tree', 'kd_tree', 'brute'}
import matplotlib.pyplot as plot
import numpy as np
import math
x = np.random.rand(100,1)
x = x * 10 - 5
y = np.array([math.sin(i) for i in x])
y = y + np.random.randn(100)
from sklearn.neighbors import KNeighborsRegressor
for i in (1,3,5,7):
for j in ('uniform', 'distance'):
for k in ('auto','ball_tree','kd_tree','brute'):
model = KNeighborsRegressor(n_neighbors=i, weights=j,algorithm=k)
model.fit(x, y)
relation_square = model.score(x, y)
print('결정계수 R:', relation_square)
print('\n')
print('\n')
y_p=model.predict(x)
plot.scatter(x,y,marker='+')
plot.scatter(x,y_p,marker='o')
plot.show()

3. K-NN 활용 수학점수로 총점 예측하기
import matplotlib.pyplot as plot
import numpy as np
import math
import pandas as pd
import seaborn as sns
import openpyxl
plot.rcParams["font.family"] = 'Malgun gothic'
data = pd.read_excel('student.xlsx', header = 0)
newData = data[['kor', 'eng', 'math', 'social', 'science', 'total']]
#속성(변수)선택
x = newData[['math']]
y = newData[['total']]
from sklearn.neighbors import KNeighborsRegressor
for i in (1,3,5,7):
for j in ('uniform', 'distance'):
for k in ('auto','ball_tree','kd_tree','brute'):
model = KNeighborsRegressor(n_neighbors=i, weights=j,algorithm=k)
model.fit(x, y)
relation_square = model.score(x, y)
print('결정계수 R:', relation_square)
print('\n')
print('\n')
y_p=model.predict(x)
plot.scatter(x,y,marker='+')
plot.scatter(x,y_p,marker='o')
plot.show()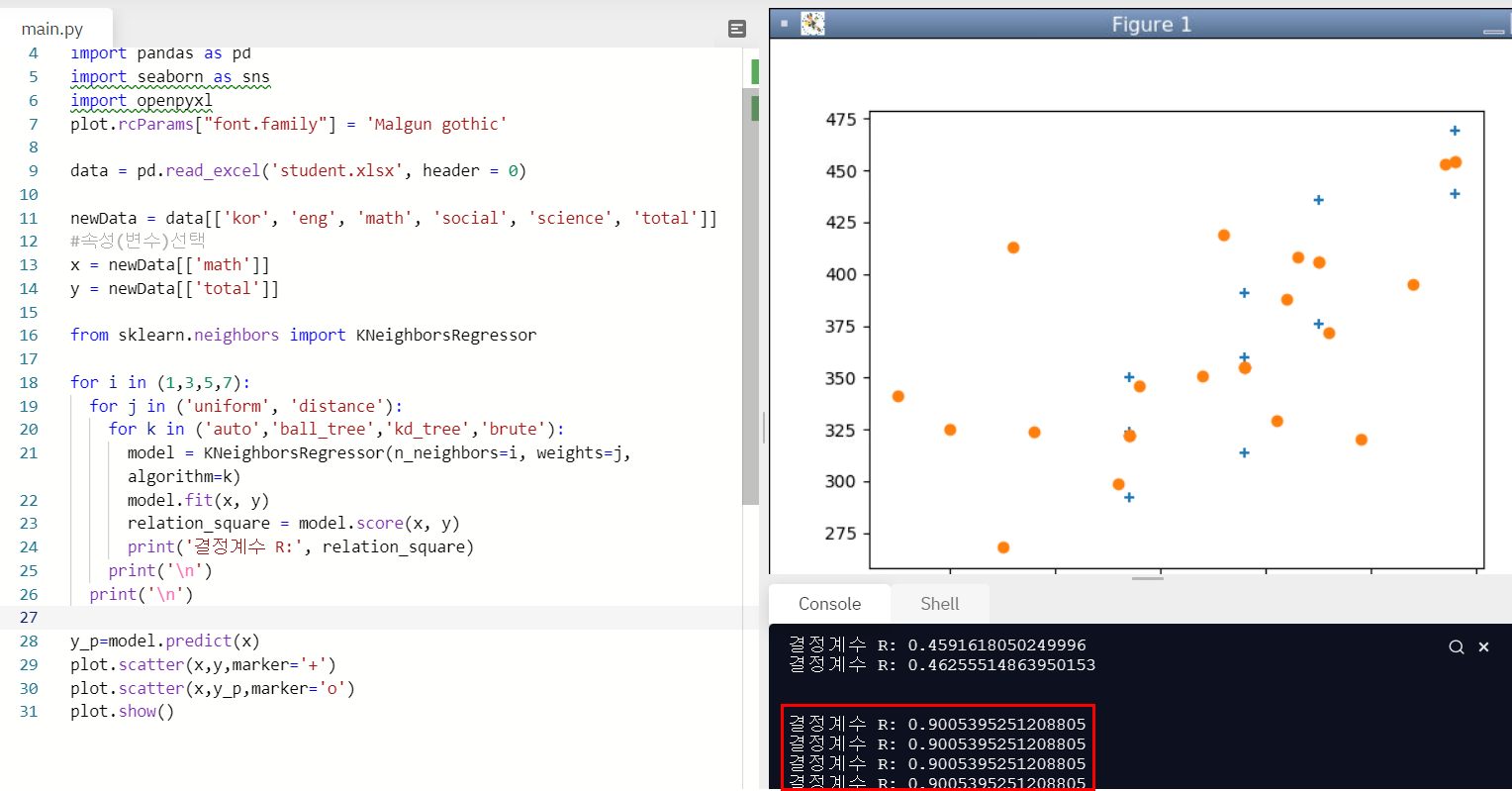
4. 국, 수, 사, 영으로 총점 예측하기
import matplotlib.pyplot as plot
import numpy as np
import math
import pandas as pd
import seaborn as sns
import openpyxl
plot.rcParams["font.family"] = 'Malgun gothic'
data = pd.read_excel('student.xlsx', header = 0)
newData = data[['kor', 'eng', 'math', 'social', 'science', 'total']]
#속성(변수)선택
x = newData[['kor', 'eng', 'math', 'social']]
y = newData[['total']]
from sklearn.neighbors import KNeighborsRegressor
for i in (1,3,5,7):
for j in ('uniform', 'distance'):
for k in ('auto','ball_tree','kd_tree','brute'):
model = KNeighborsRegressor(n_neighbors=i, weights=j,algorithm=k)
model.fit(x, y)
relation_square = model.score(x, y)
print('결정계수 R:', relation_square)
print('\n')
print('\n')
y_p=model.predict(x)
ax1 = sns.distplot(y, hist = False, label = 'y_실제')
ax2 = sns.distplot(y_p, hist = False, label = 'y_예측')
plot.show()
반응형
'프로그래밍 > 머신러닝' 카테고리의 다른 글
| 인공신경망(neural_network)_파이썬으로 머신러닝 배우기 (0) | 2021.05.05 |
|---|---|
| 결정 트리(Decision Tree)_파이썬으로 머신러닝 배우기 (0) | 2021.05.03 |
| 그레이디언트 부스팅(GradientBoostingRegressor)_파이썬으로 머신러닝 배우기 (0) | 2021.04.26 |
| 랜덤 포레스트(RandomForestRegressor)_파이썬으로 머신러닝 배우기 (2) | 2021.04.26 |
| 서포트 백터 머신(model = SVR(kernel = 'rbf', C=1000, gamma = 1000)_파이썬으로 머신러닝 배우기 (0) | 2021.04.23 |



