그레이디언트 부스팅 모듈 사용해보기!
1. 그레이디언트 부스팅이란?
이전 트리의 오차를 보완하는 방법
(랜덤 포레스트를 개선한 방법이다!)
특징
강력한 가지치기
트리의 깊이가 깊지 않다.
무작위성이 없다.
매개 변수 조절이 힘들다.
2. 인자 결정
n_estimator : 트리의 수
max_depth : 트리의 깊이
max_features : 나누는 수
Learning rate : 학습률
랜덤 포레스트에서는 트리의 수가 가장 중요한 인자이고
그레이디언트 부스팅은 트리의 수와 학습률 두 가지가 중요한 인자이다.
3. 그레디언트 부스팅 실제로 사용해보기!
x, y 를 랜덤 데이터로 만들어주고 그레디언트 부스팅 모듈을 사용해 예측해보자!
import matplotlib.pyplot as plot
import numpy as np
import math
x = np.random.rand(100,1)
x = x * 10-5
y = np.array([math.sin(i) for i in x])
y = y + np.random.randn(100)
from sklearn.ensemble import GradientBoostingRegressor
for i in (10, 20, 30, 40, 100, 150):
for j in (0.001, 0.01, 0.1):
model = GradientBoostingRegressor(n_estimators = i, learning_rate = j, max_depth = 4)
model.fit(x, y)
relation_square = model.score(x, y)
print('결정계수 : ', relation_square)
y_p = model.predict(x)
plot.scatter(x,y, marker = 'x')
plot.scatter(x,y_p, marker = 'o')
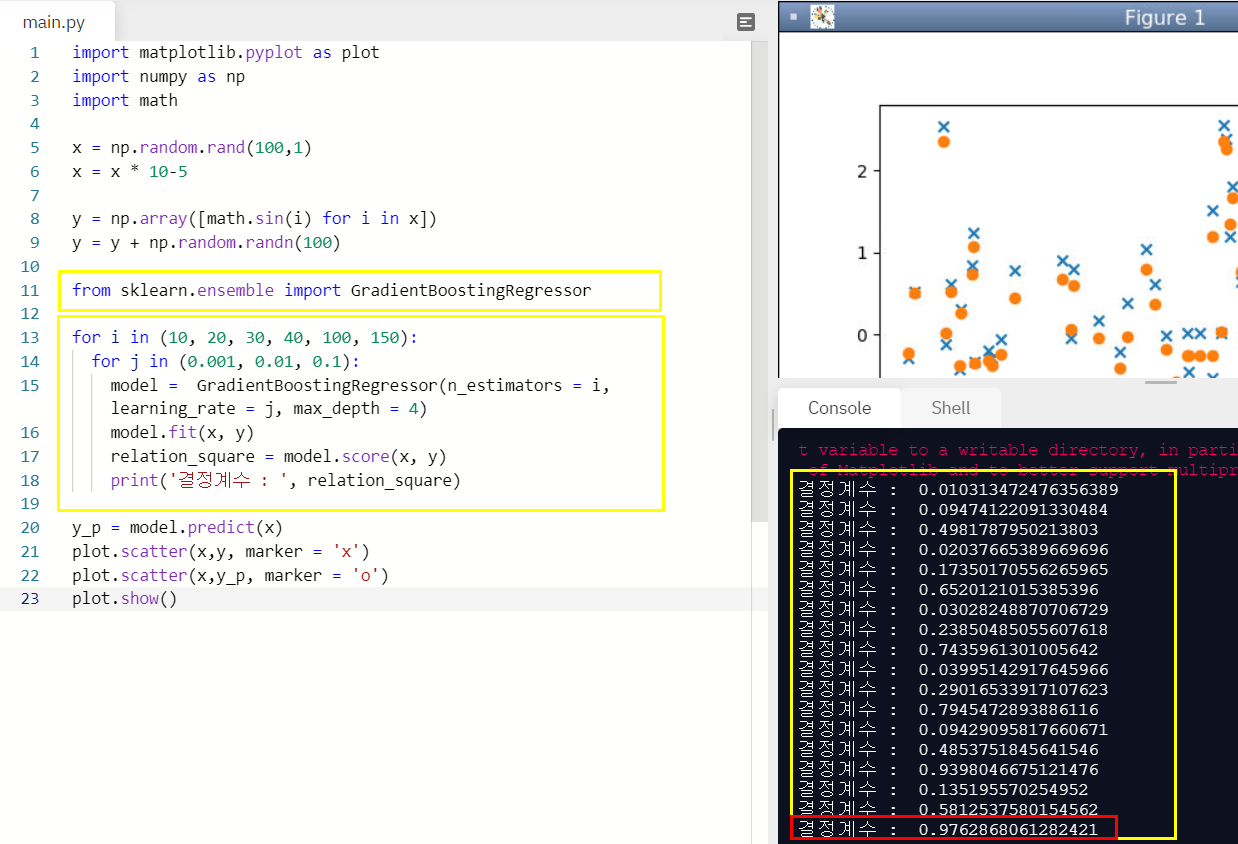
plot.show()결정계수를 18개의 경우의 수로 나누어 살펴보았다!
n_estimators가 150일때와 learning_rate가 0.1일때 결정계수가 0.9762로 가장 높았다!
확실히 랜덤 포레스트보다 결정계수가 높다!
4. 수학 성적으로 총점 예측하기!
랜덤 포레스트에서 했던 것처럼 그레이디언트 부스팅을 이용해 수학 점수로 총점을 예측해보자~!
import matplotlib.pyplot as plot
import numpy as np
import math
import pandas as pd
import seaborn as sns
import openpyxl
plot.rcParams["font.family"] = 'Malgun gothic'
data = pd.read_excel('student.xlsx', header = 0)
newData = data[['kor', 'eng', 'math', 'social', 'science', 'total']]
#속성(변수)선택
x = newData[['math']]
y = newData[['total']]
from sklearn.ensemble import GradientBoostingRegressor
for i in (10, 20, 30, 40, 100, 150):
for j in (0.001, 0.01, 0.1):
model = GradientBoostingRegressor(n_estimators = i, learning_rate = j, max_depth = 4)
model.fit(x, y)
relation_square = model.score(x, y)
print('결정계수 : ', relation_square)
y_p = model.predict(x)
ax1 = sns.distplot(y, hist = False, label = 'y_실제')
ax2 = sns.distplot(y_p, hist = False, label = 'y_예측')
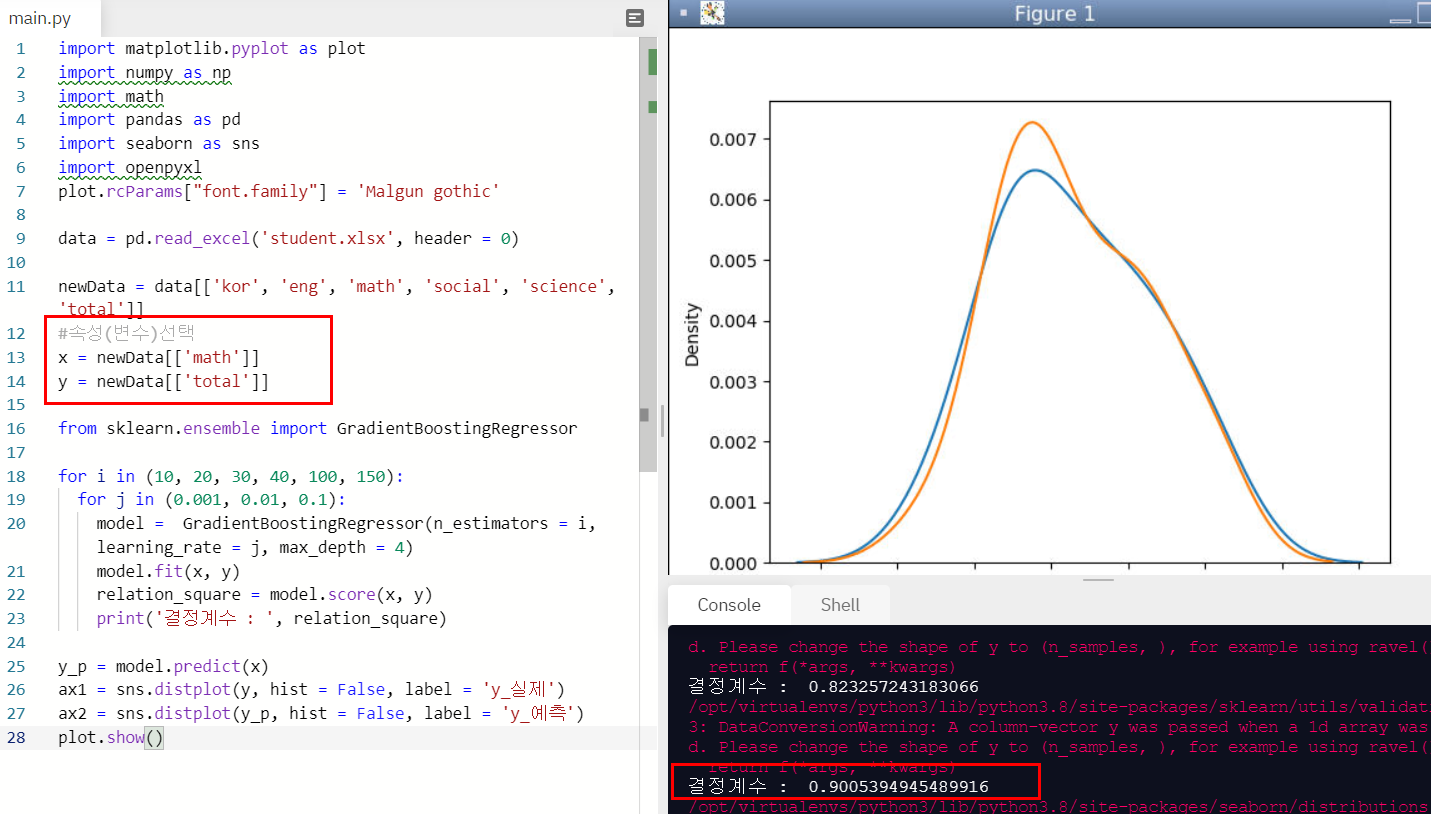
plot.show()
결정계수가 0.9005까지 나왔다. 확실히 랜덤 포레스트보다 높게 나왔다.
하지만 최고는 SVR인것 같다.
5. 국, 수, 사, 영으로 총점을 예측해보자!
국, 수, 사, 영어 점수로 총점을 예측해보자.
import matplotlib.pyplot as plot
import numpy as np
import math
import pandas as pd
import seaborn as sns
import openpyxl
plot.rcParams["font.family"] = 'Malgun gothic'
data = pd.read_excel('student.xlsx', header = 0)
newData = data[['kor', 'eng', 'math', 'social', 'science', 'total']]
#속성(변수)선택
x = newData[['kor', 'eng', 'math', 'social']]
y = newData[['total']]
from sklearn.ensemble import GradientBoostingRegressor
for i in (10, 20, 30, 40, 100, 150):
for j in (0.001, 0.01, 0.1):
model = GradientBoostingRegressor(n_estimators = i, learning_rate = j, max_depth = 4)
model.fit(x, y)
relation_square = model.score(x, y)
print('결정계수 : ', relation_square)
y_p = model.predict(x)
ax1 = sns.distplot(y, hist = False, label = 'y_실제')
ax2 = sns.distplot(y_p, hist = False, label = 'y_예측')
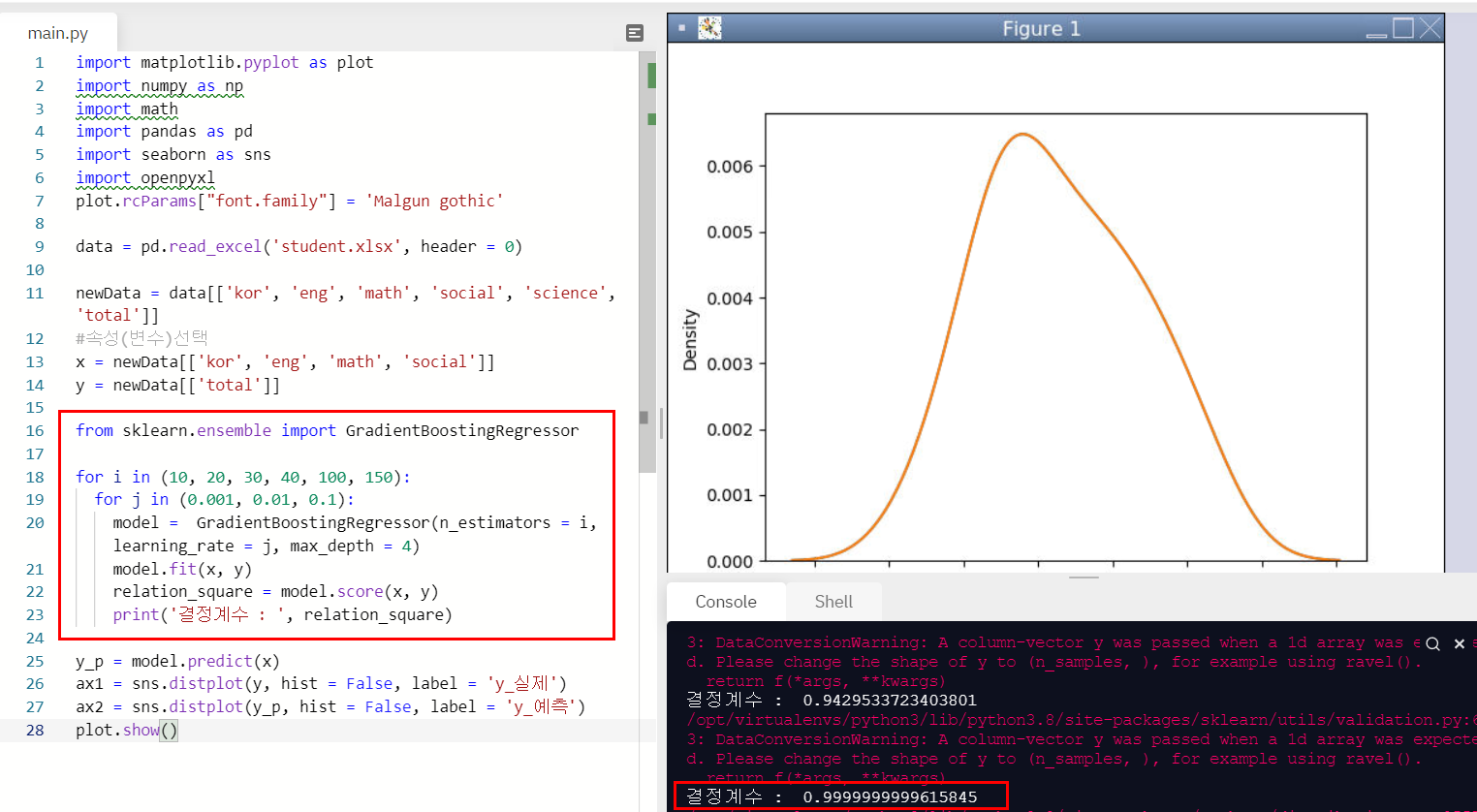
plot.show()와... 결정계수가 0.999999까지 나왔다!
SVR만큼이나 높은 수가 나왔다!
6. 에이다 부스트(AdaBoost) 모듈 사용해보기
에이다 부스트도
n_estimators, learning_rate를 조절해주면 된다!
에이다 부스트를 사용한 경우 수학점수로 총점을 예측하는 결정계수는 0.8043이 최대로 나왔다.
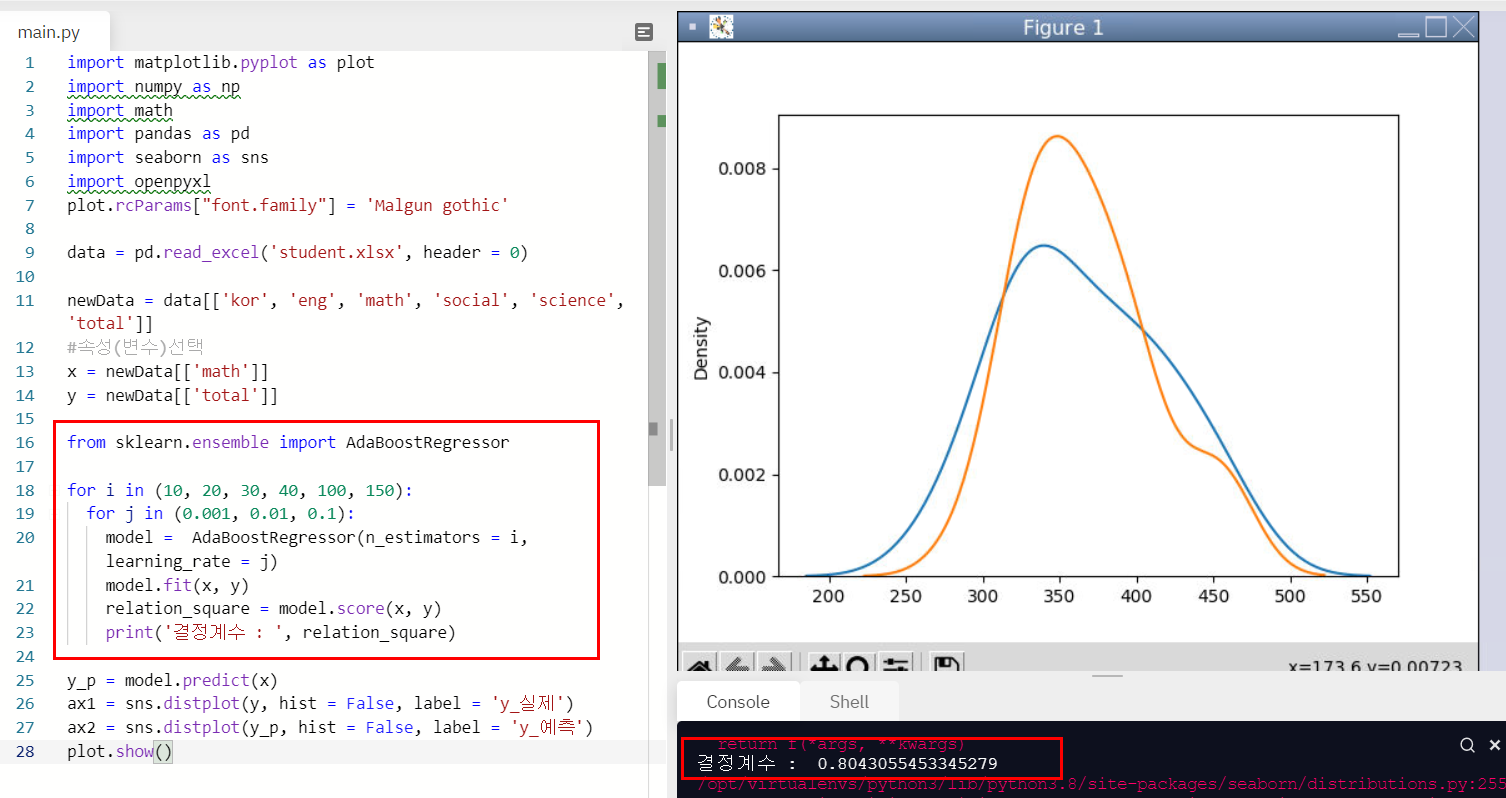
결정계수 : 0.8043055453345279
여러 모듈을 활용해보면서 가장 최적의 모듈을 선택하고 인자를 적절하게 조정해주는 것이 필요할 듯 하다!
'프로그래밍 > 머신러닝' 카테고리의 다른 글
| 결정 트리(Decision Tree)_파이썬으로 머신러닝 배우기 (0) | 2021.05.03 |
|---|---|
| k-근접 모델(KNeighborsRegressor)_파이썬으로 머신러닝 배우기 (0) | 2021.04.29 |
| 랜덤 포레스트(RandomForestRegressor)_파이썬으로 머신러닝 배우기 (2) | 2021.04.26 |
| 서포트 백터 머신(model = SVR(kernel = 'rbf', C=1000, gamma = 1000)_파이썬으로 머신러닝 배우기 (0) | 2021.04.23 |
| 서포트 백터 머신(from sklearn.svm import SVR)_파이썬으로 머신러닝 배우기 (1) | 2021.04.21 |



